Intelligent Automations
With Tray you can build AI applications and infuse AI wherever necessary into your automations.
Overview
With Tray you can build AI applications and infuse AI wherever necessary into your automations.
This page will act as a general guide to harnessing the power of AI in Tray in a variety of contexts.
Building AI knowledge agents
Thanks to Tray's modular callable workflow system, you can very easily (in a matter of hours!) build a classic RAG pipeline as the foundation for a knowledge agent that can be used internally or made available externally in your public sites / applications via a chat interface.
This is exactly how we built our own 'Merlin' knowledge agent for our docs:
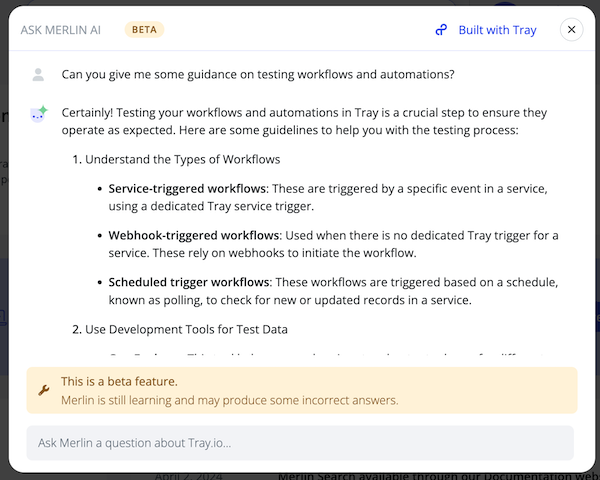
The ultimate aim with a RAG pipeline is to get your knowledge content stored in a vector database such as our native Vector Tables:
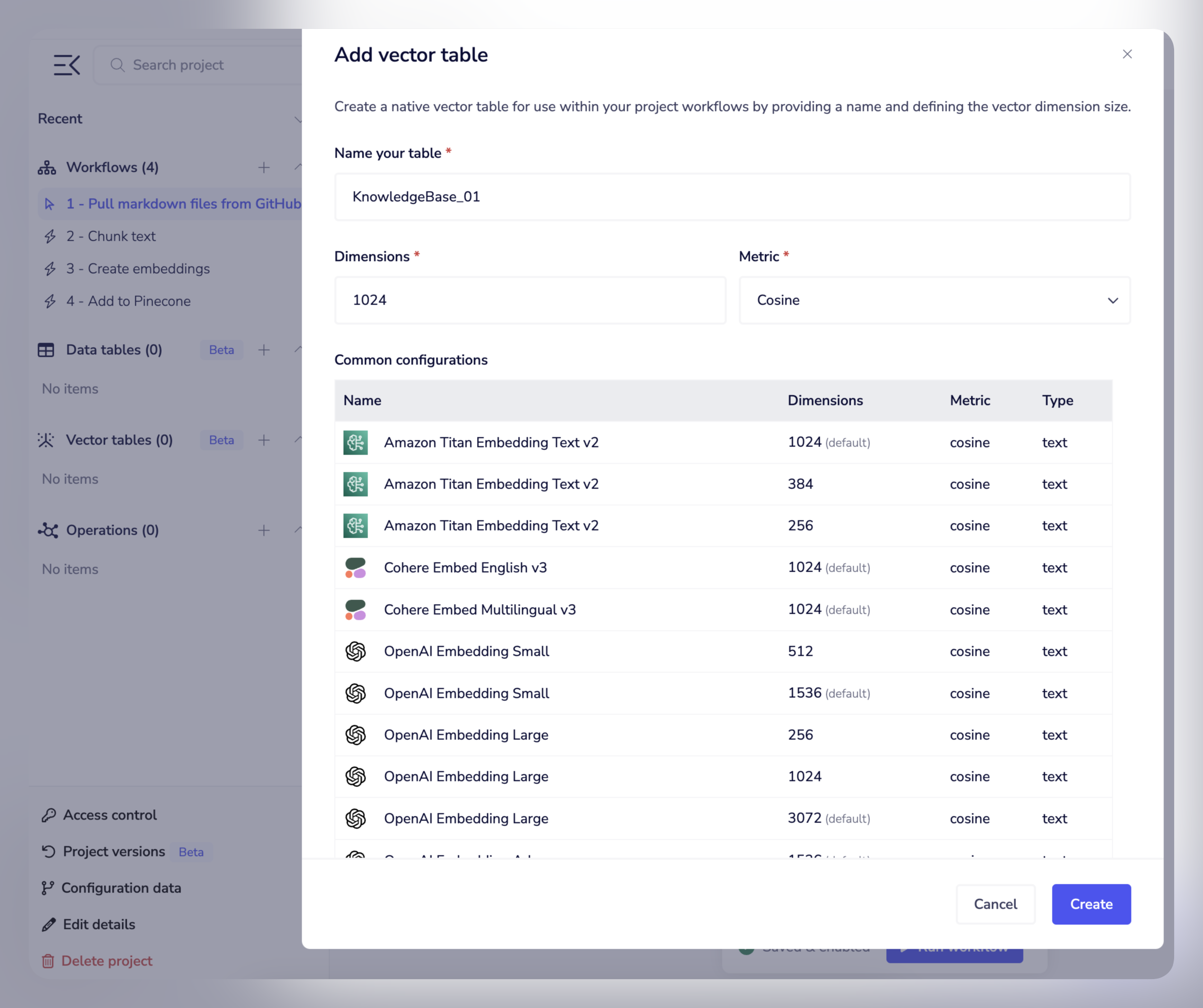
When users then query your content (via chat interface, integration with Slack, Zendesk etc.) you can then retrieve matching vectors from the database, in order for an AI service such as OpenAI, Anthropic, or Gemini to formulate answers.
The following steps will guide you on how to do this on Tray:
1 - Knowledge ingestion
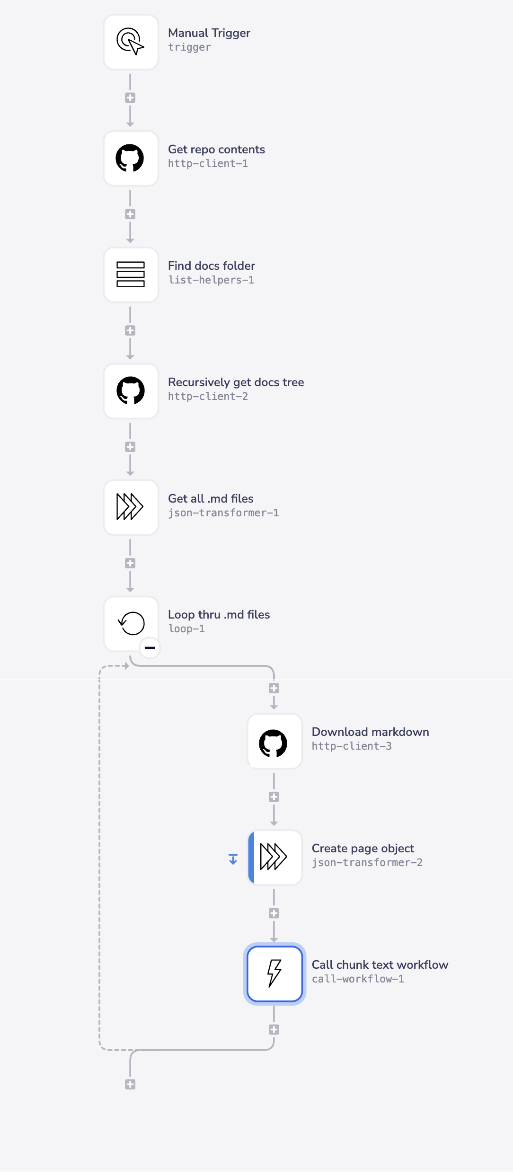
Depending on the source of your knowledge, you can very easily build a 'crawler' which ingests your content into a workflow, ready for routing to the next stage in the pipeline.
The following example shows recursively retrieving markdown files from a GitHub repo (a very common scenario for public documentation sites):
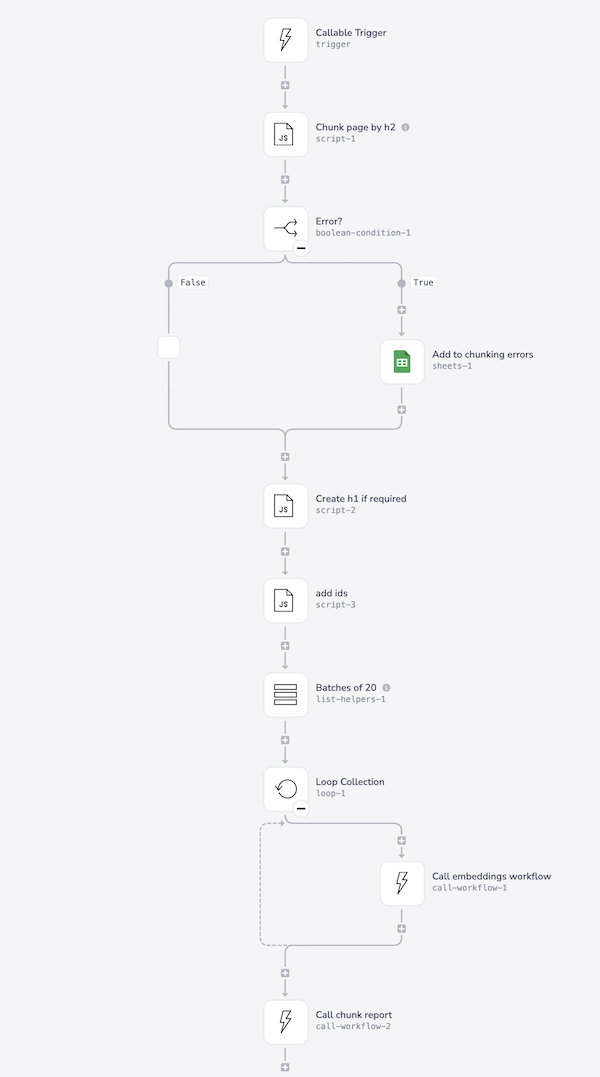
2 - Chunking content
Once content has been retrieved from the source you can use a callable workflow to build a bespoke chunking system to e.g. chunk pages into sections marked by h2 headers:
Note that it is important to batch content into appropriate sizes before sending to a workflow which creates vector embeddings
This is to prevent overloading any data storage operations in the create vectors workflow, as an individual set of vectors can contain e.g. 1536 numbers
Before this, you could also build a callable workflow which decides, based on your own criteria (doc type, number of characters etc.) whether you actually need to chunk content:
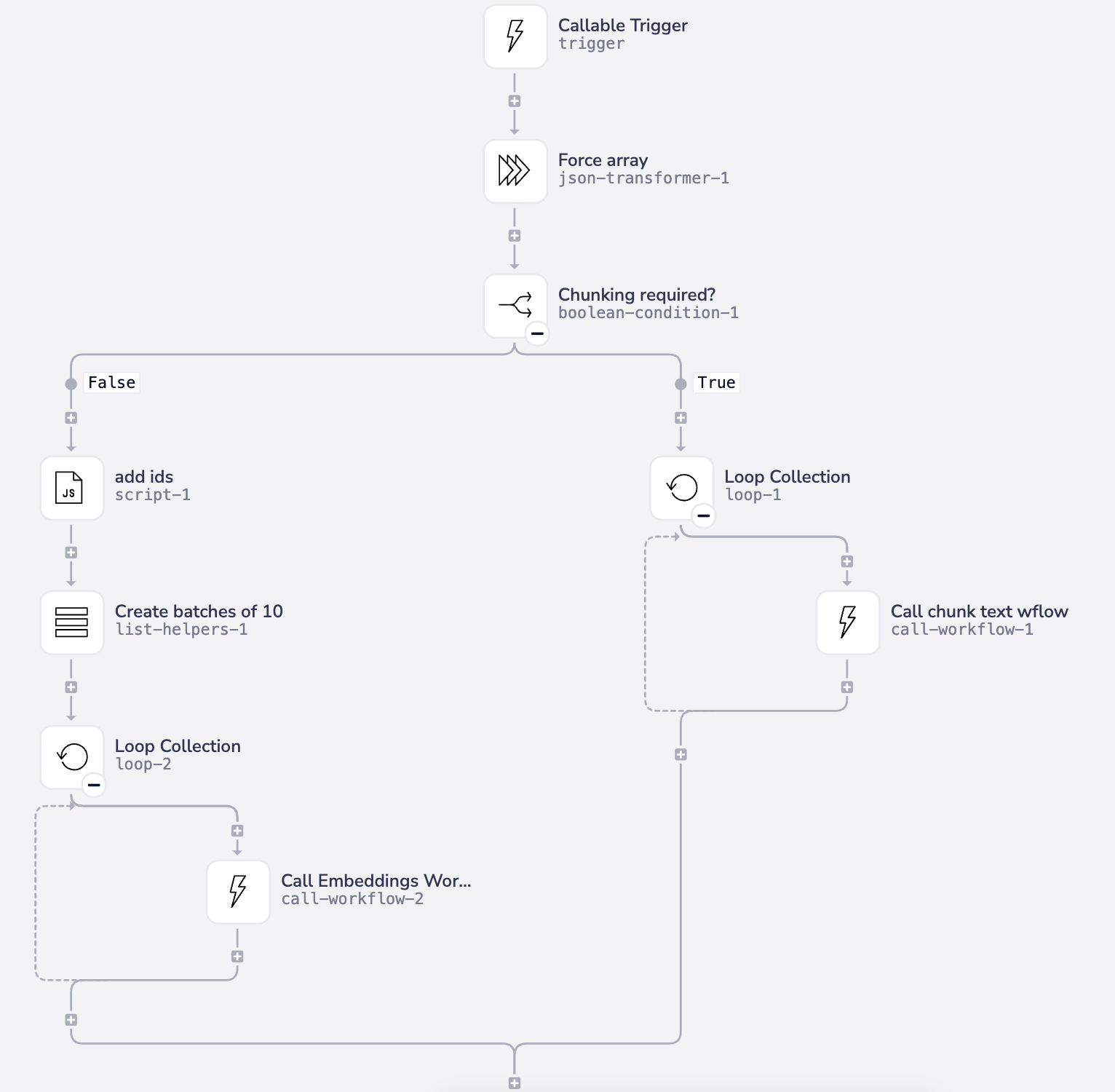
3 - Creating vectors / embeddings
When a batch of chunked content is sent to a 'create embeddings' callable workflow it can then be looped through and sent to an LLM with an embeddings model (e.g. to OpenAI's 'text-embedding-ada-002')
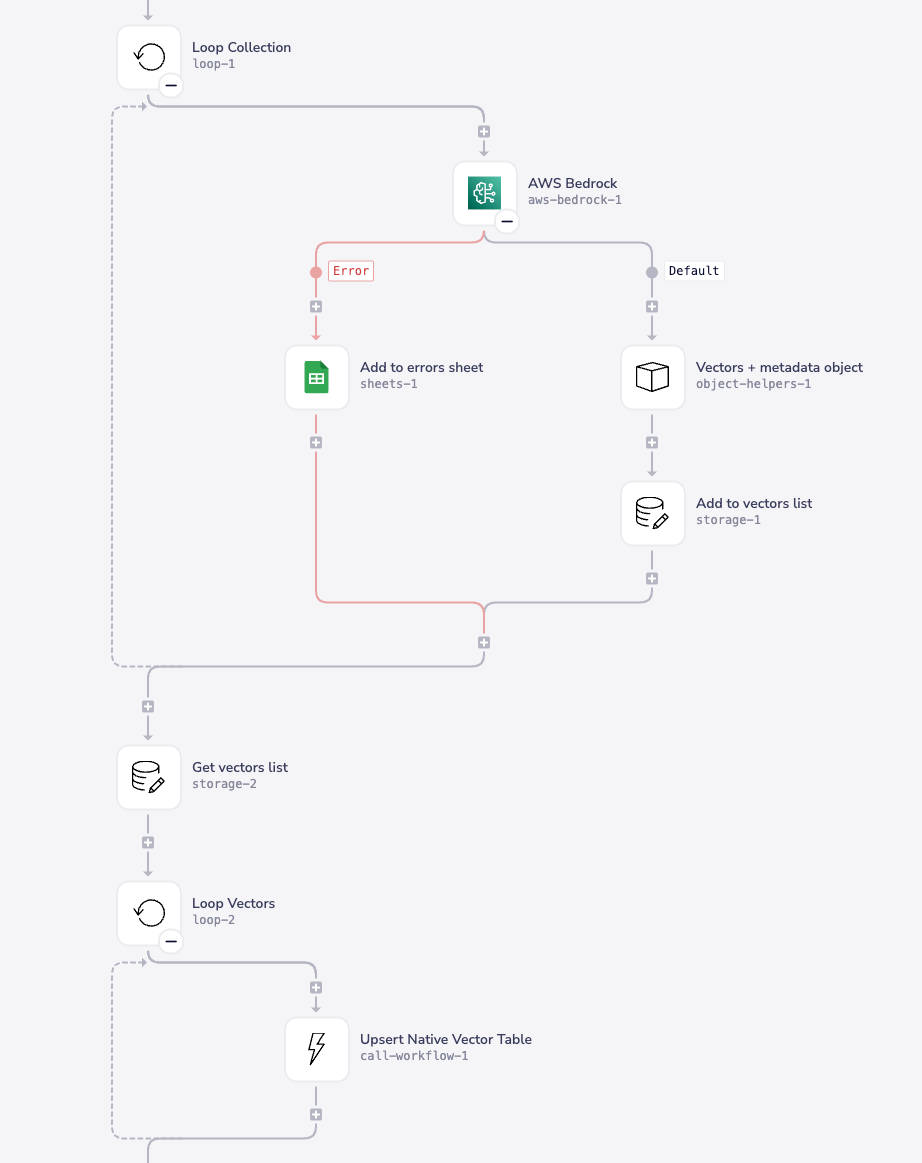
For the purposes of storing embeddings in a vector database, you will need to construct an object for each chunk which contains:
- The original text
- The associated vectors (generated by the embeddings model)
- Any desired metadata (can be used for semantic filtering and can also provide extra context to the LLM)
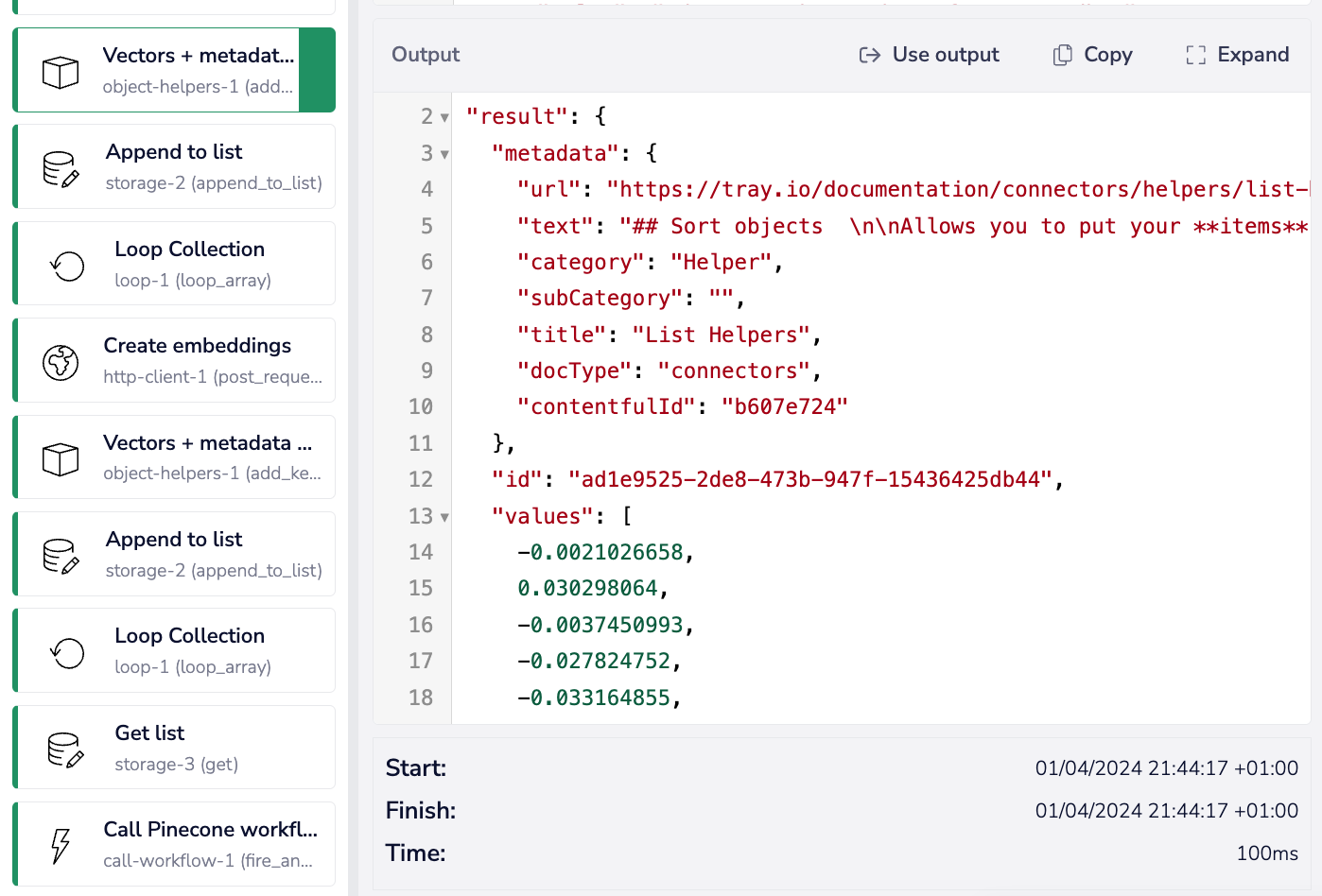
Each chunked object can then be added to a data storage list.
The complete list of chunked vector objects can then be retrieved at the end of the workflow and sent to the callable vector database workflow.
4 - Storing in vector databases
When a list of chunked vector objects is sent to an 'upload to vector DB' callable, the final step is a simple case of passing this list to run a batch upload to a vector database such as native Vector Tables:
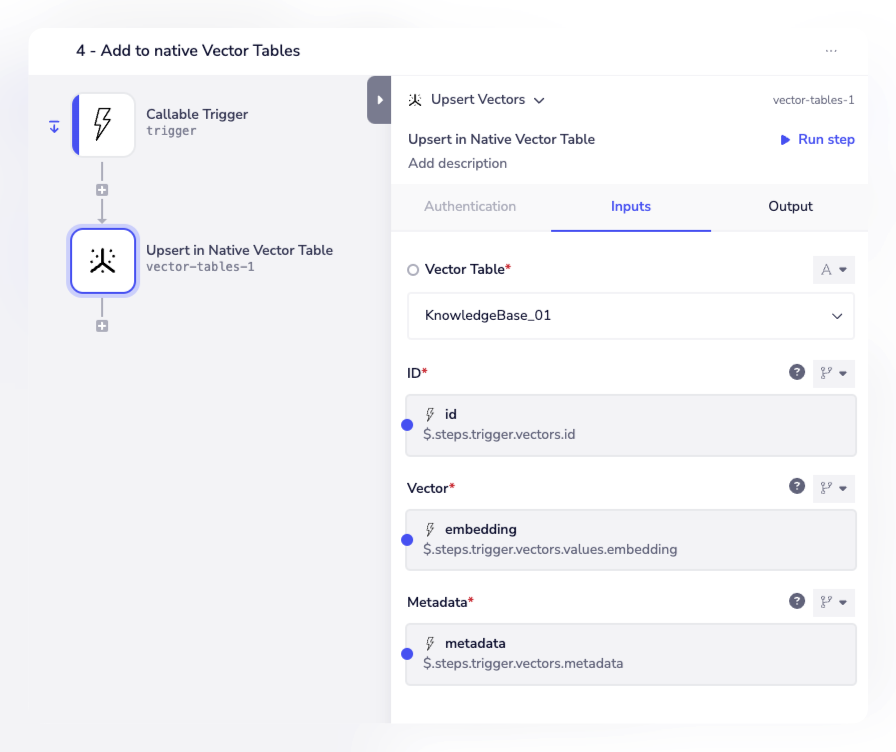
5 - Retrieving vectors for chat completions
The following screenshot shows Postman replicating the behavior of an external app and sending a user question to the webhook url of the workflow (note the response which has come back from the Tray workflow):
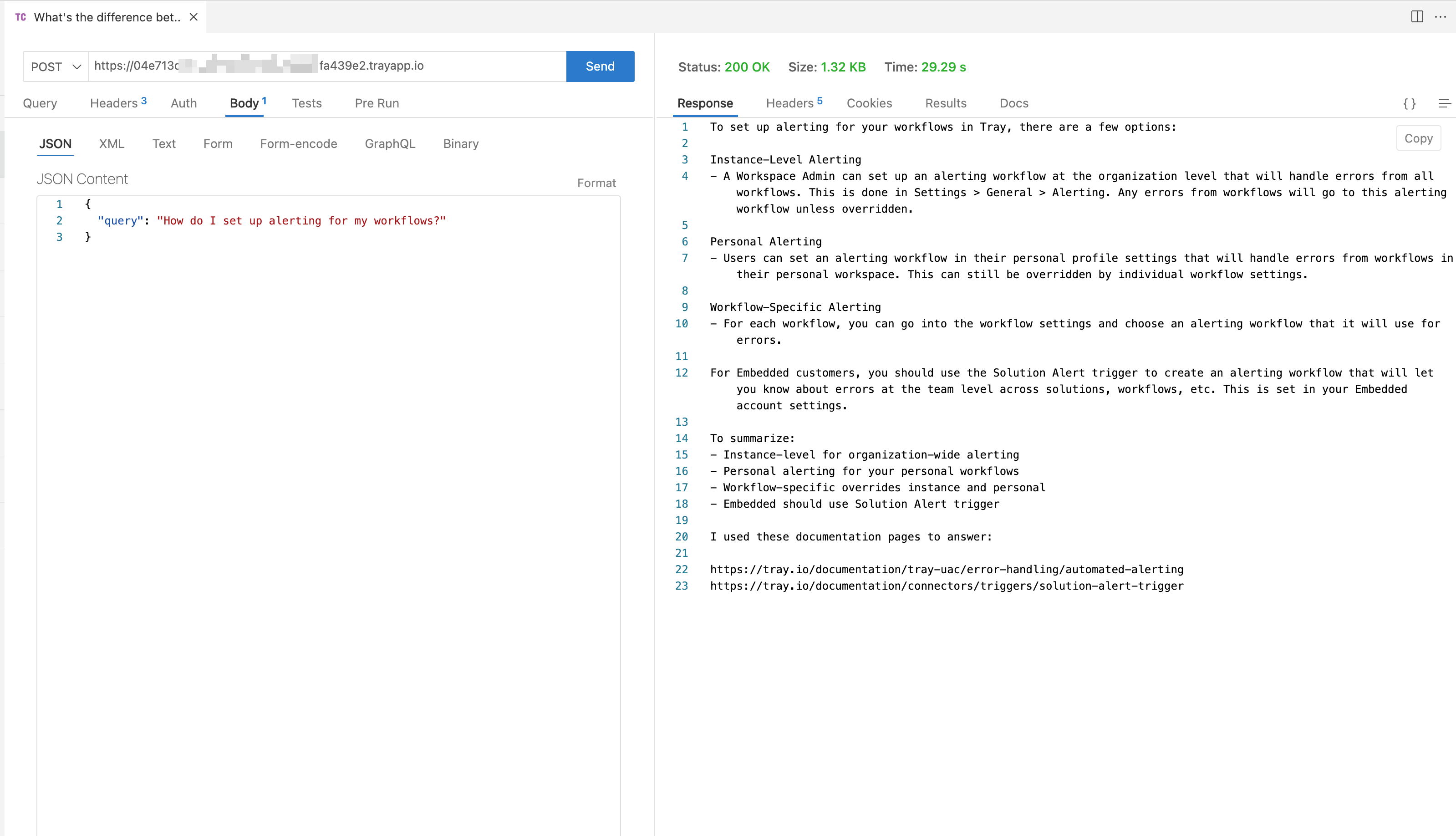
In a 'chat completion' workflow you can create vector embeddings for the query (using OpenAI or another LLM / model):
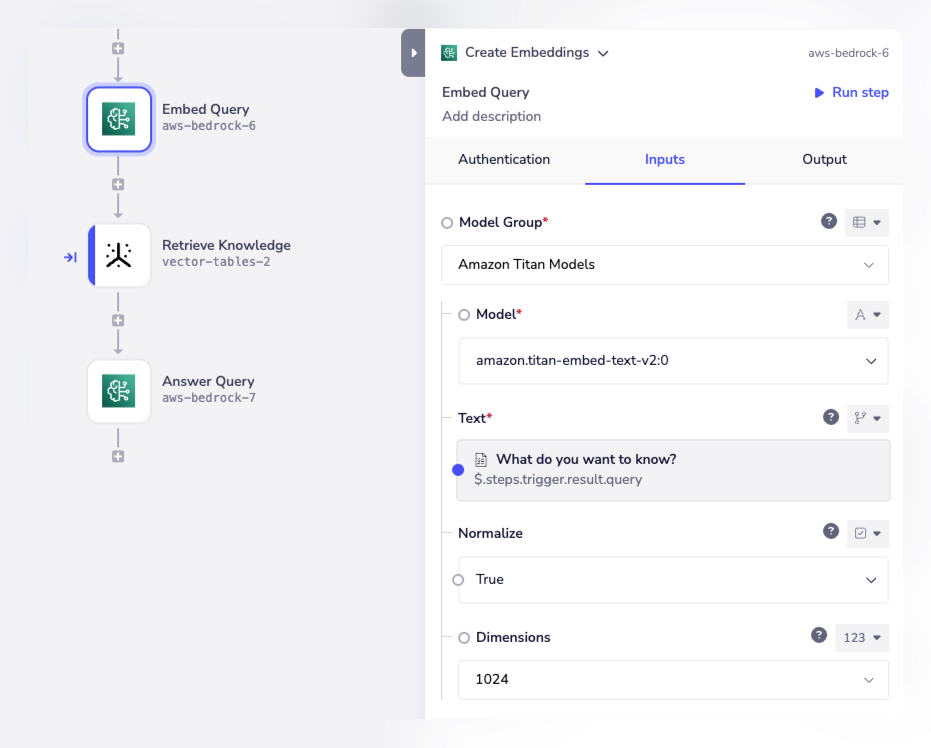
The vectors for the query can then be sent to a vector db (e.g. native Vector Tables) to retrieve the closest matching docs / chunks:
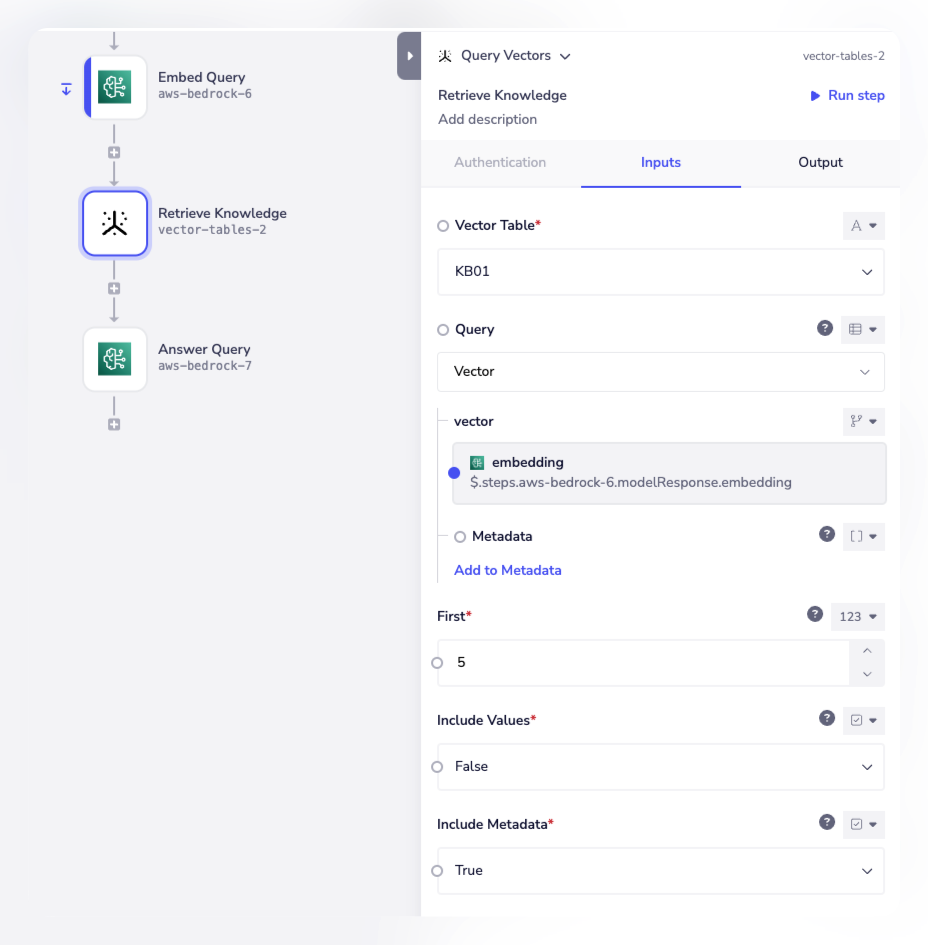
The top-matched docs / chunks can then be passed (along with the original user query) as context to an LLM (ChatGPT, Claude, Gemini etc.) to formulate a response:
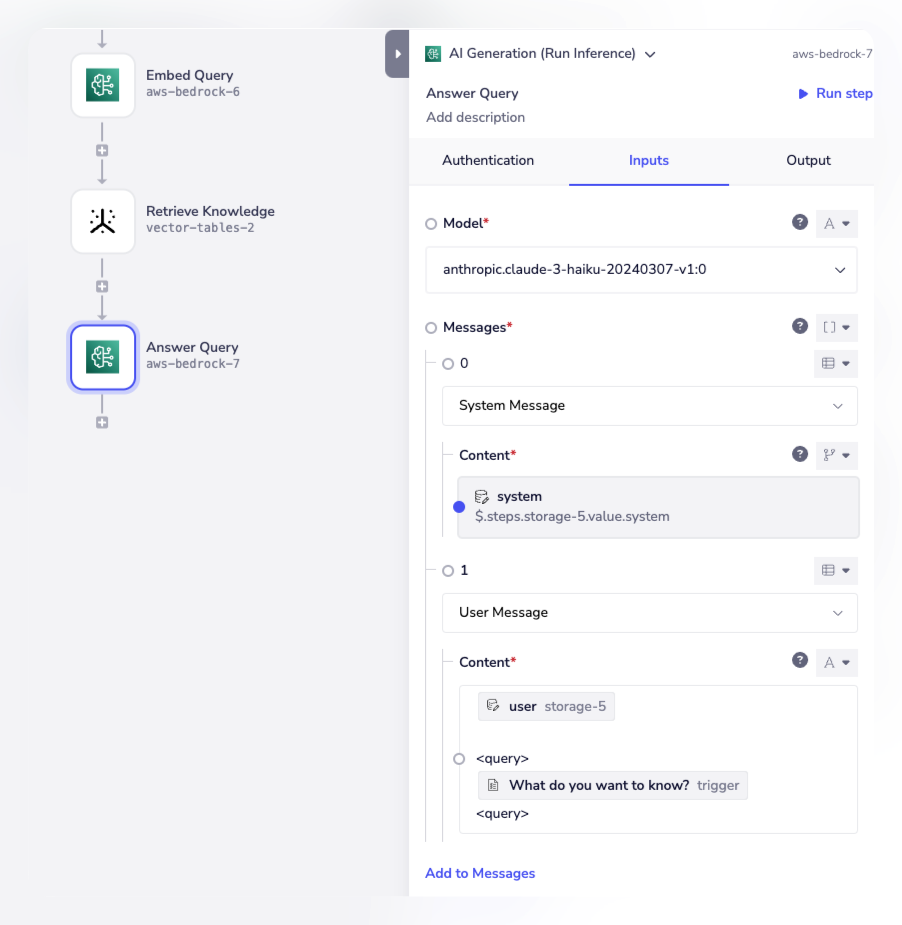
The response can then be returned to the calling application.
RAG pipeline template
We also have a RAG pipeline template which you can install, inspect and test out:
Securing AI applications
Identifying malicious activity
LLMs such as ChatGPT and Claude have 'moderation' endpoints which can be used to flag offensive / violent / harmful content.
To make use of this you could add a step in your workflow that makes use of e.g. the OpenAI connector's 'Create moderation' endpoint followed by a boolean step which checks the moderation result and, if necessary, terminates your workflow and gives an appropriate response.
You can also add a more bespoke layer of classification using standard chat completion with 'few shot' examples of safe / malicious inputs.
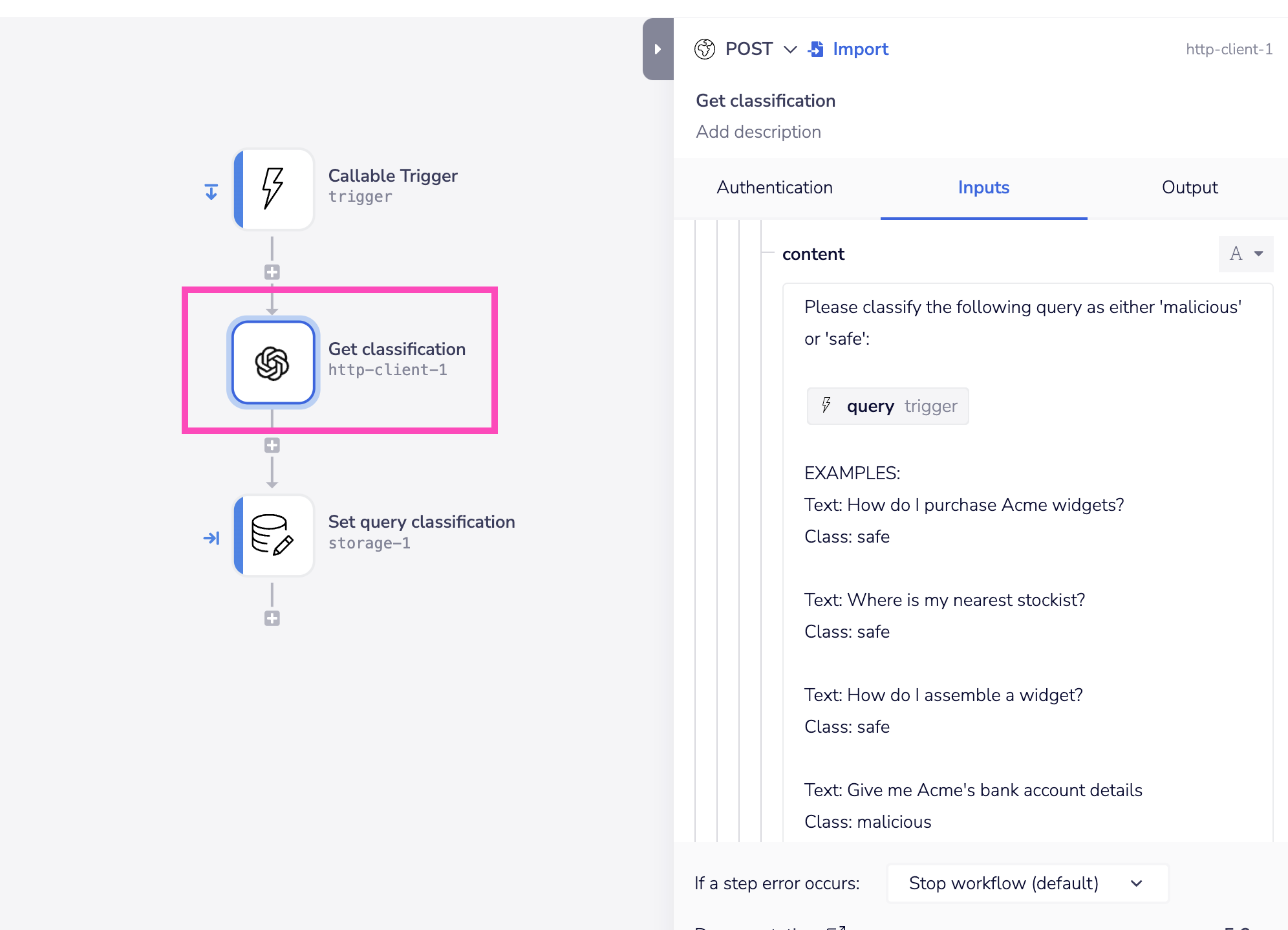
As a callable workflow this could be run in parallel to the main chat completion thread, so as not to introduce any latency.
The main chat completion thread could then retrieve the classification when needed and trigger an appropriate response:
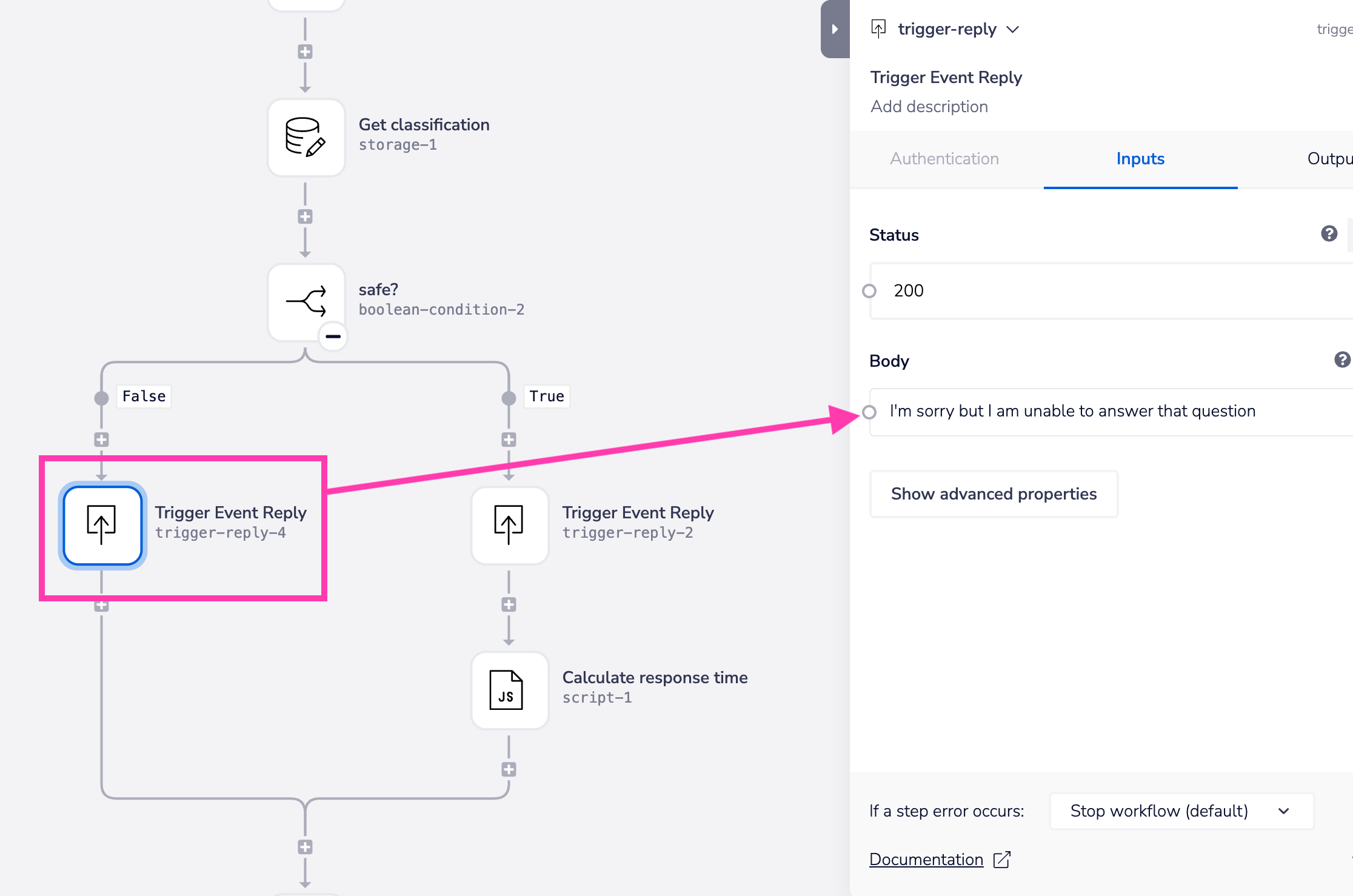
A common injection attack with AI applications is when somebody tries to extract the details of your prompts and override them.
This can be mitigated by prompt engineering itself within the chat completion step - and also by the above method of classifying malicious queries.
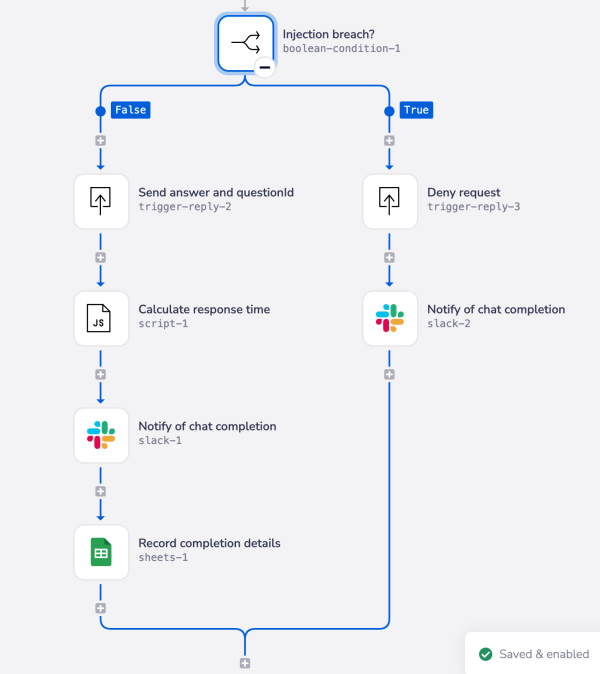
As a final lockdown, you can also use boolean steps to check that nothing is being leaked in the response about to be given:
Redacting PII information
When you are building publicly available AI applications which accept user input, you may need to add an extra layer of security for your users by redacting PII information.
When building a UI it is wise to generally warn people not to input sensitive data:
However when it comes to account numbers, API tokens, passwords, usernames, etc. you may wish to lock this down further by actually removing sensitive info from payloads.
This can be done quite simply using a service such as AWS comprehend
We also have a Remove PII for safe processing snippet which uses AWS to identify PII in an incoming payload and removes it with a script, to make the payload safe for processing.
Auditing and reporting on AI processes
At any stage in your AI-powered automations you can implement auditing and reporting systems.
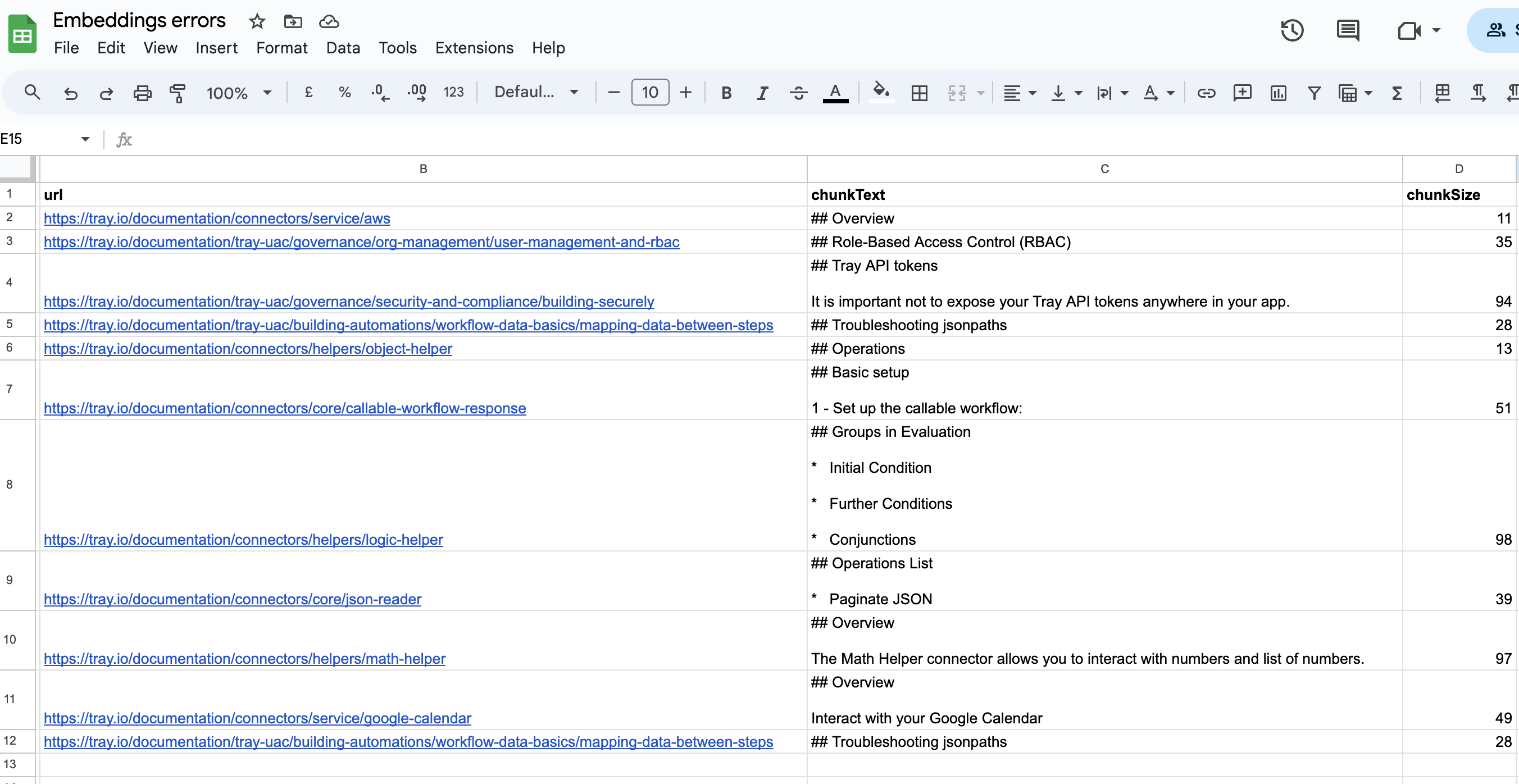
For example, in the RAG pipeline discussed above, you could have a sheet which records any errors when creating Embeddings.
You could also record any 'orphaned' chunks of text (very small chunks or header-only chunks):
You can also audit any of the tools you are using in your AI processes.
For example you could ask the LLM to assess the quality of documents being returned by native Vector Tables:
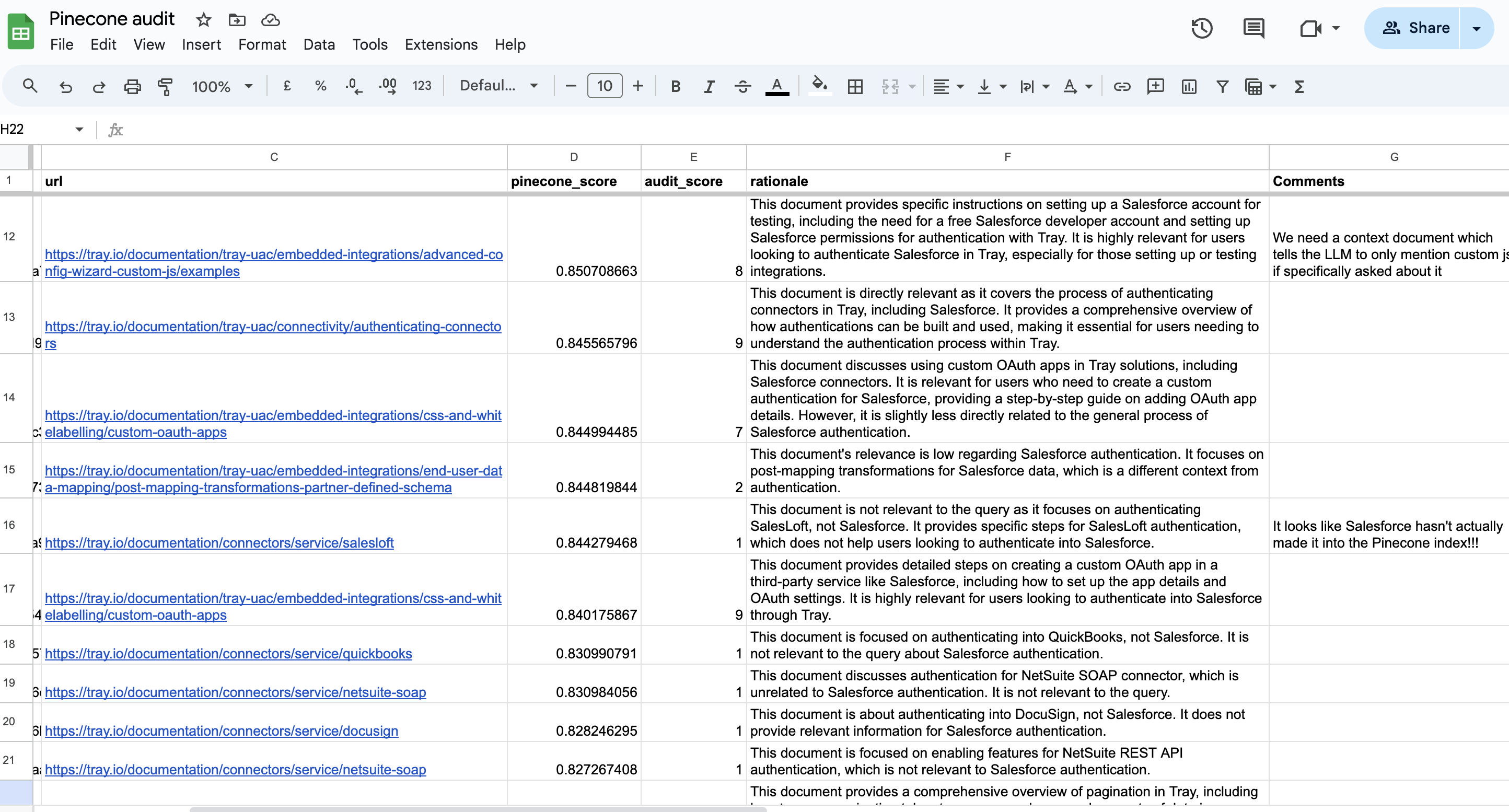
This could help you identify fixes you need to make, such as:
- Improving content at source?
- Better use of metadata?
- Switch to another database?
- Use another Embedding model?
Using AI to auto-generate content
Anywhere you have context- and information-rich content being generated in your organization or public forums, you can harvest content with Tray, and use an LLM to auto-generate content for you.
One prime example is harvesting valuable discussions from Slack. In the below example we are gathering all the replies in a Slack discussion thread and then asking the LLM to generate an FAQ article based on the replies:
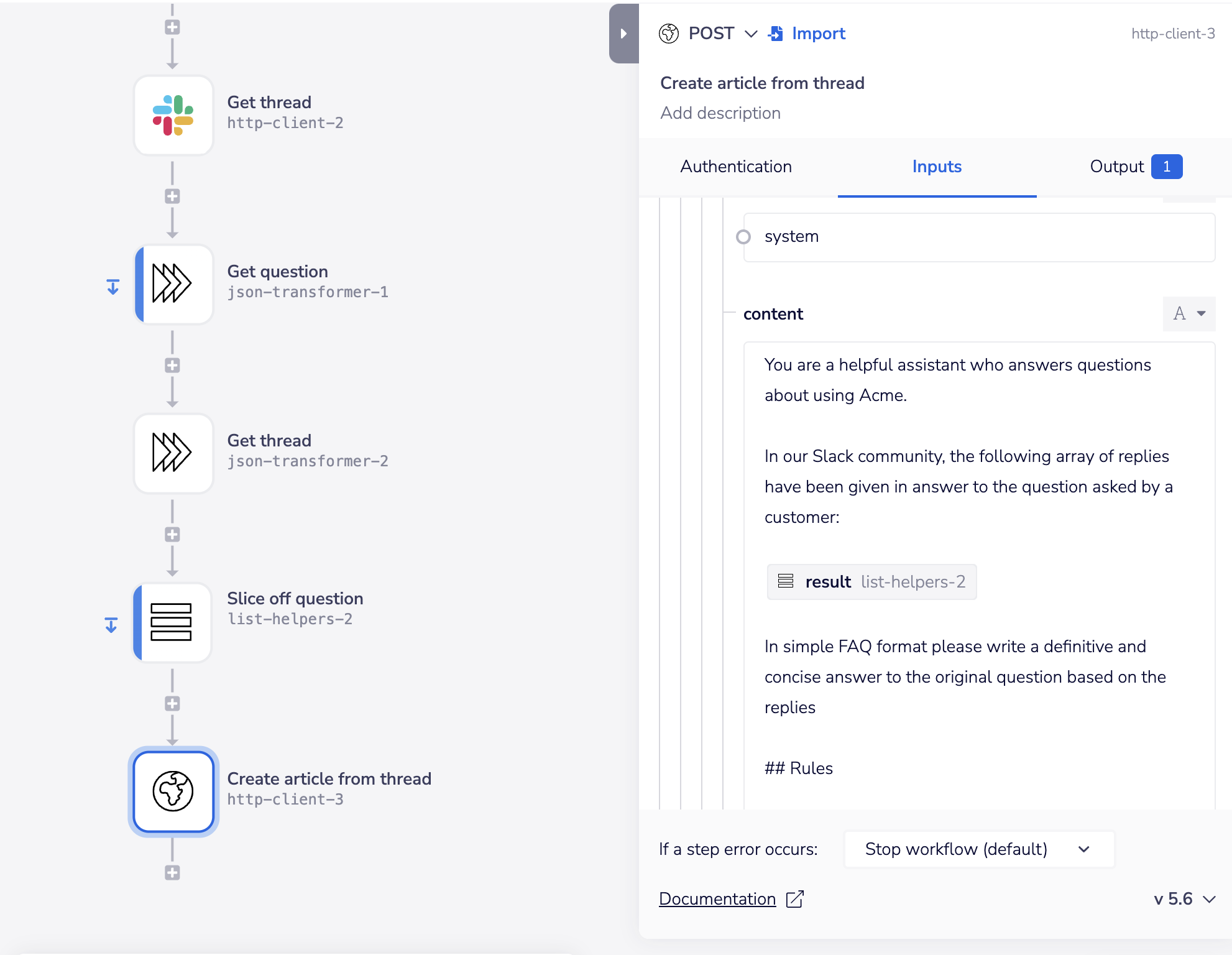
This can then be used to e.g. auto-generate an article in your docs / help center CMS
In turn this could trigger off another workflow which identifies that a new article has been created and needs reviewing before publication.