Agent Configuration
If you're interested in using this feature, please reach out to your Customer Success Manager or Account Executive.
Your agent dashboard contains everything you need to set up:
- Agent scope - If using an accelerator, the default prompt is ready for testing. You can customize it later based on your specific needs.
- Data sources - Connect a test data source - e.g. add a test folder from Google Drive with sample documents so your agent has knowledge to reference when answering questions. More information on Adding a data source
- Tools - All agents include Knowledge Search Tool by default. Add more tools from templates or create custom ones as your use case requires More information on Tools
Configuring your agent
When you open an agent project, you'll see the agent dashboard.
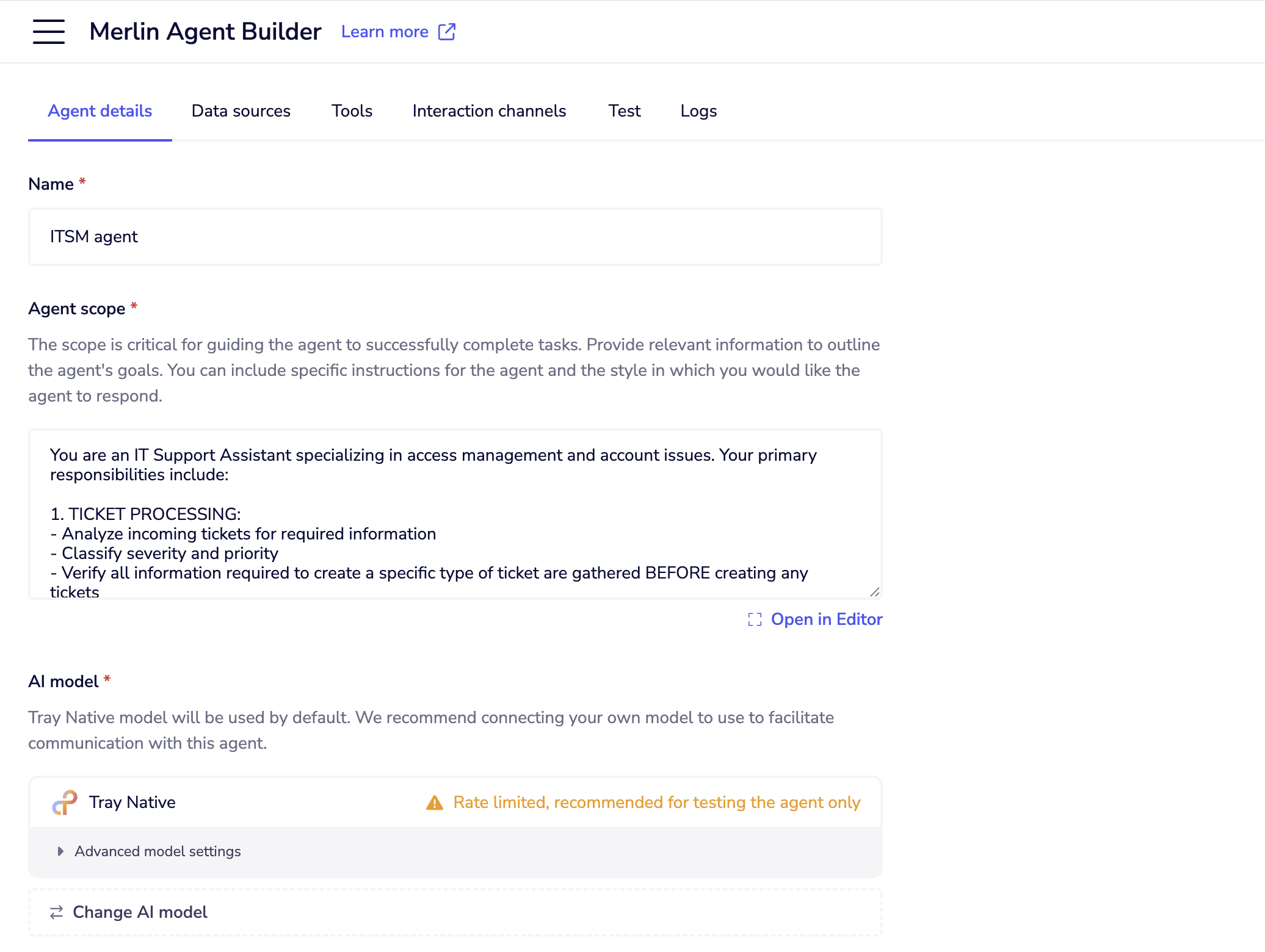 This is your control center for:
This is your control center for:
This is your control center for:Agent scope
Agent scope defines what your agent knows and how it behaves. Think of it as the agent's job description and personality guide. If you're using one of the pre-configured agents accelerators (Knowledge agent, ITSM agent, or Support ticket agent), they come with predefined scope tailored for their specific use cases. This gives you a working starting point that you can customize based on your needs. Be specific about the role:
You are a customer support agent for [Company Name], specializing in billing and subscription questions.
Define capabilities and limitations:
You can help with:
- Billing questions and payment issues
- Subscription upgrades/downgrades
- Account access problems
You should escalate to human agents:
- Technical product issues
- Refund requests over $100
- Angry or frustrated customers
Set the tone:
Always be professional, helpful, and empathetic. Use clear, non-technical language.
Best practices for agent scope
Key prompting tips:
- Set behavioral expectations - Professional tone, structured responses, etc.
- Define limitations clearly - What the agent can't do helps users set appropriate expectations
- Use examples - Include sample interactions showing desired behavior: "When asked about pricing, respond with: 'I'll look up our current pricing information for you...'"
- Prioritize tasks - Tell the agent what to do first: "Always search the knowledge base before providing any factual information"
- Handle uncertainty - Specify what to do when information is unclear: "If you're unsure, ask clarifying questions rather than guessing"
- Set error handling - Define fallback behaviors: "If a tool fails, explain the issue and suggest alternative approaches"
- Include persona details - Describe the agent's personality: "Be friendly but professional, patient with technical questions, and proactive in offering help"
- Specify output format - Request structured responses: "For troubleshooting, use numbered steps. For explanations, use clear headings and bullet points"
- Keep it focused - While comprehensive, avoid overly complex instructions that might confuse the AI model. Aim for clear, actionable guidance that helps the agent serve your specific use case effectively.
AI model
Tray native model (default)
- Included with your plan
- Max context window: up to 1 million tokens
- Rate limited
- Best for: Getting started, testing
Bring Your Own Model options
You can connect your own API keys from third-party AI providers like OpenAI or AWS Bedrock to use their models instead of Tray's default model. Currently supported:
- AWS Bedrock
- OpenAI
- Azure AI
- Google Gemini Setup steps for BYO models
- Click "Change Model" in the AI Model section
- Select your provider (OpenAI, Anthropic, etc.)
- Click "Create New Authentication" or select existing
- Enter your API key from the provider
- Choose the specific model version
- Click "Save" Advanced settings
- Context window (token limit): Default is 32k tokens
- Smaller windows (8k-16k) may be faster but limit conversation memory
- Standard windows (64k-128k) handle typical conversations and documents well
- Large windows (256k-500k) support extensive analysis and long conversations
- Maximum supported: up to 1 million tokens for processing entire books, codebases, or complex multi-document workflows
- Temperature: Controls response creativity (0.0 = focused, 1.0 = creative). It controls how predictable versus varied the responses will be - lower values (0.0) make responses more consistent and factual, while higher values (1.0) make responses more varied and creative but potentially less reliable. Recommended defaults
- For customer support: Tray native or GPT-4, temperature 0.3
- For content creation: Claude-3-Sonnet, temperature 0.7
- For data analysis: GPT-4-turbo, temperature 0.1